Firstly we need to understand the prediction errors in ML algorithms to measure the accuracy of machine learning algorithms. Bias and Variance are two prominent Machine Learning model errors. Reducing bias errors increases variance and vice-versa. There we need to make a bias variance tradeoff while deciding on ML model performance.
A better understanding of the Bias Variance Tradeoff helps in avoiding overfitting and underfitting problems in Machine Learning Models. We can also control Bias and Variance using Regularization techniques.
To understand Bias Variance Tradeoff, firstly we need to understand What is Bias and Variance?
Table of Contents
ToggleWhat is Bias?
Bias is an error in ML model predictions that consistently deviate from true values. Mathematically bias is equal to the difference between ML model predictions with true values.

The high-bias model more likely underfits the training data and gives a high error in both the training and test datasets.
- A bias equal to zero indicates that the model predictions are accurate.
- We need to make sure our ML algorithms are low-biased to avoid under-fitting problems.
- The linear regression model has a high bias.
Bias errors in the Machine Learning model can be due to the following reasons:
- Wrong Assumptions (considering data is linear when it is quadratic).
- Training data is not representative.
- Wrong algorithm selection.
What is Variance in Machine Learning?
Variance indicates variability in ML model predictions for a given data point. Generally, we face this issue when the ML model is highly complex with a large number of features.
A high-variance machine learning model is a model that is highly sensitive to training data. This model does not generalize on unseen validation data.
The high-variance model more likely overfits the training data and gives a high error in test datasets.
- A variance equal to zero indicates that the model predictions are accurate.
- We need to make sure our ML algorithms have low variance to avoid under-fitting problems.
- The Decision Tree and Support Vector Machine (SVM) model in ML has a high bias.
Variance errors in the Machine Learning model can be due to the following reasons:
- ML model is highly sensitive to training data.
- Machine Learning model is highly complex with a large number of features.
Bias Variance Tradeoff
The best ML algorithm is with low bias and low variance. In the ideal condition, we want zero bias and zero variance. But it’s not possible in the real world.
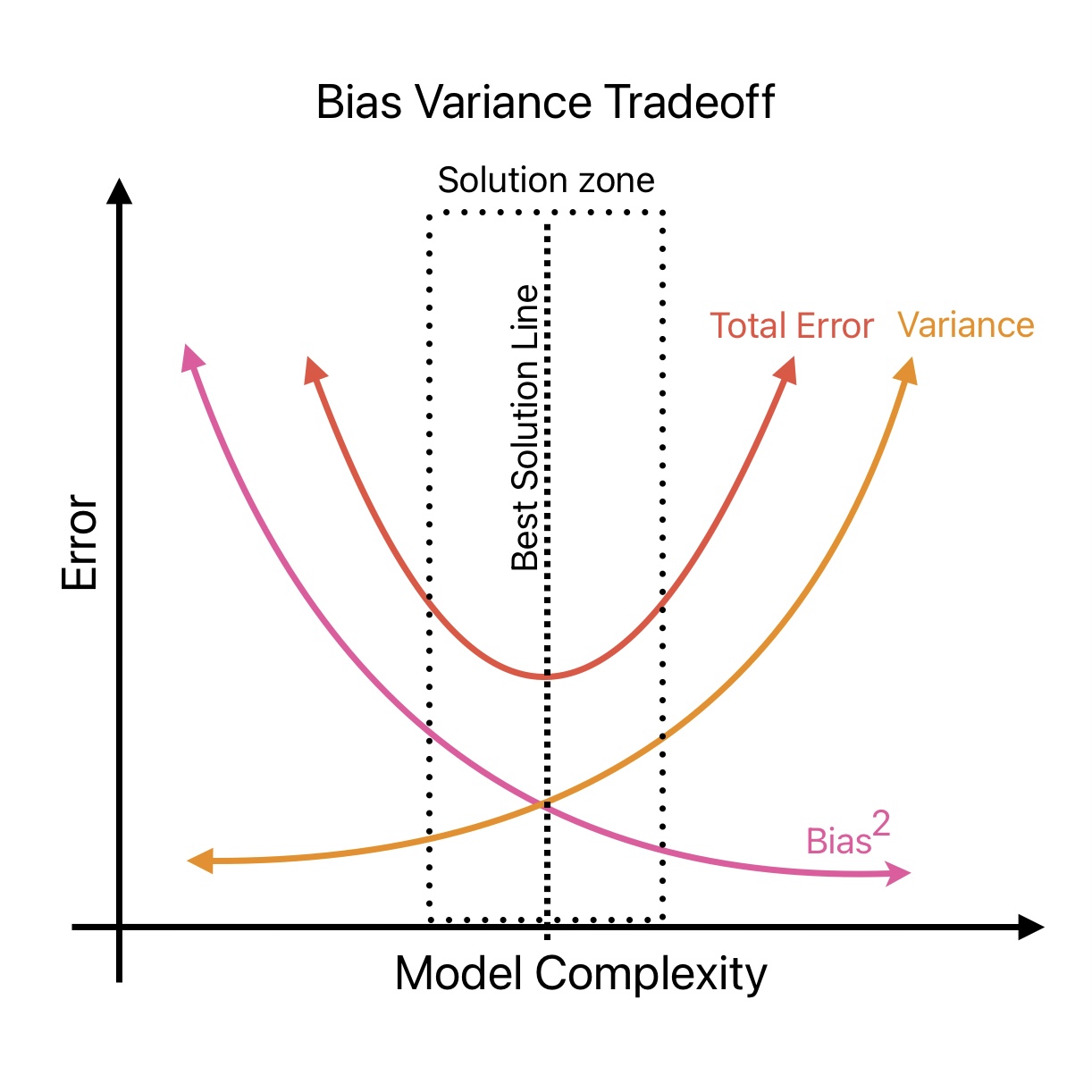
If our ML algorithm is too simple (a straight line), High bias and low variance conditions may arise. Whereas, if our ML algorithm is very complex (A line fitting all the training data points)
We need to increase the training instances to reduce bias. However, more training instances increase the variance. Therefore, we need to strike a balance between variance and bias during ML model developments.
How to make decision on Bias Variance Tradeoff
During ML model developments, we need to finalize a value for bias and variance that minimizes total error.
- Increasing a model’s complexity will typically increase its variance and reduce its bias.
- Reducing a model’s complexity increases its bias and reduces its variance.
This is why we call it a tradeoff.
We can use the following two techniques to decide on a bias-variance tradeoff.
- Learning Curves: It shows the impact of the number of samples in training data on ML model performance.
- Plot training and validation error for different values of degree of polynomial.
- Plot training and validation error for different values of a hyperparameter that controls the model complexity.