Overfitting and underfitting are the common machine learning problems that impact the ML model performance. We can build effective ML algorithms if we know in detail about the overfitting and underfitting of ML models.
Table of Contents
ToggleOverfitting and Underfitting in Machine Learning
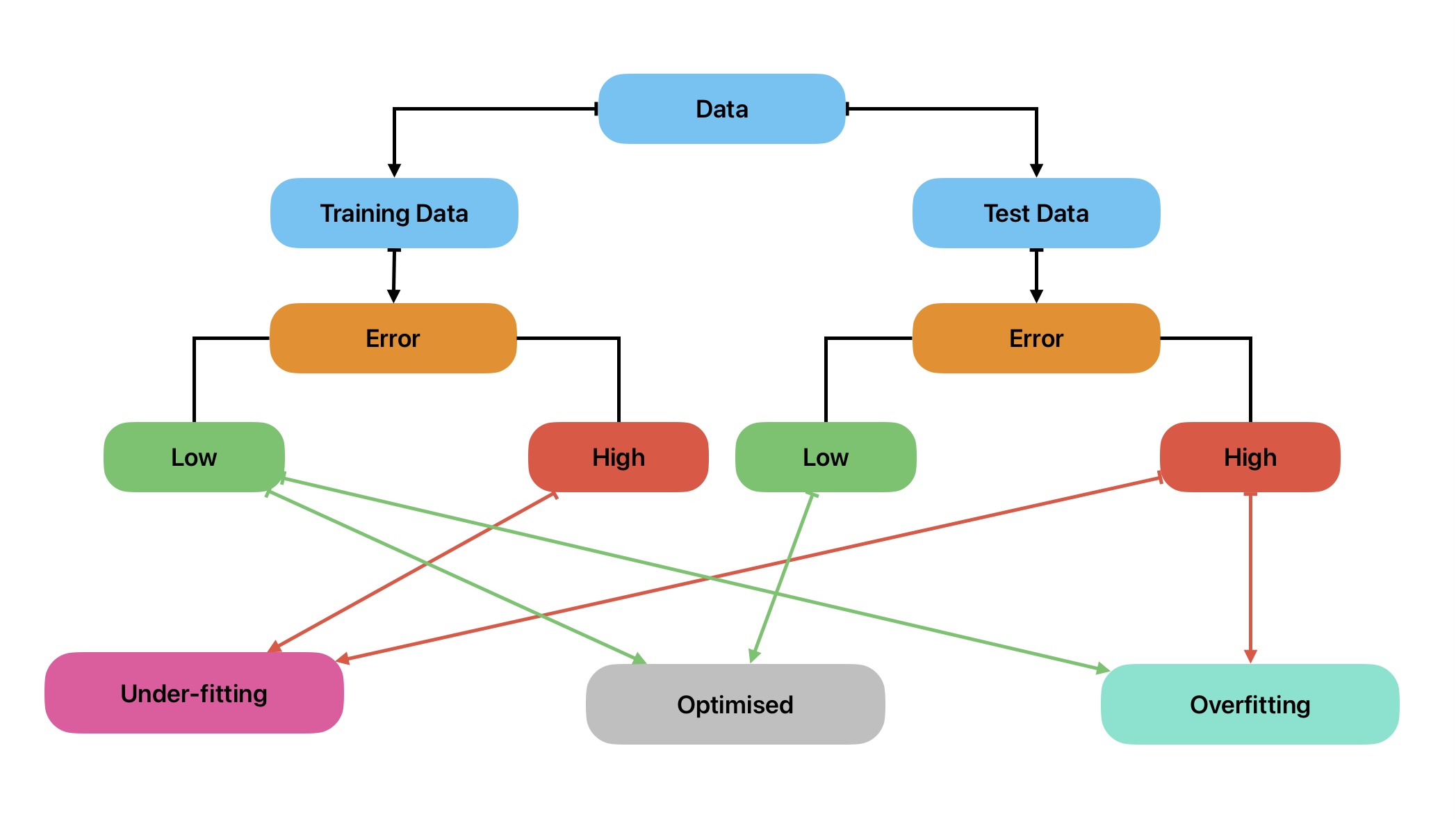
A common practice in ML model development is to first split the data into training and test data. Afterward, ML model performance is evaluated on training and test data to reduce overall error. Bias and variance and terms that are used to control overfitting and underfitting in ML algorithms.
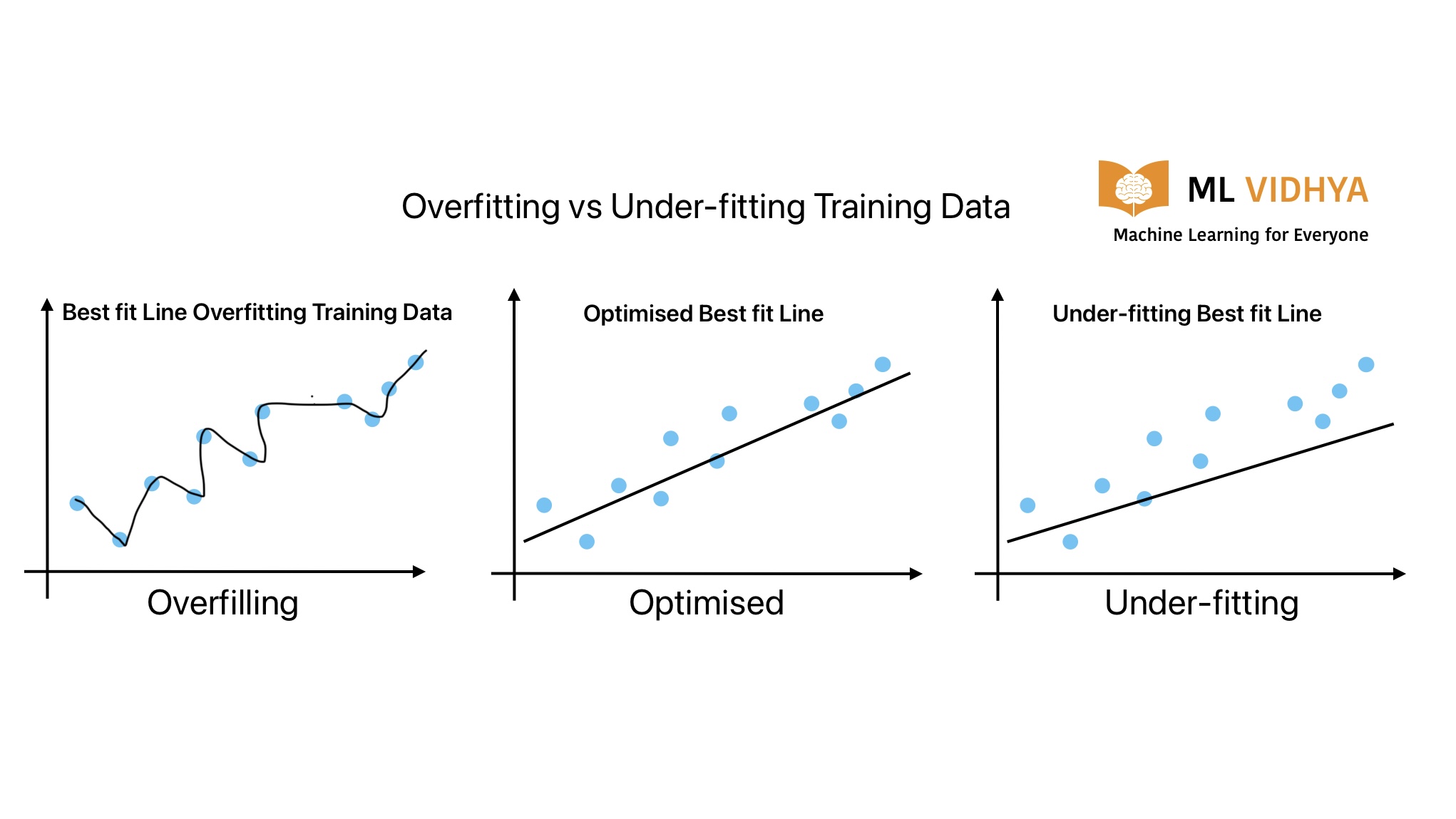
Overfitting in Machine Learning
In layman’s language, from a student’s perspective, overfitting is like remembering all the answers. But you will not be able to answer the question if you get different questions in the exam because the student does not understand the concept, he just remembered the answers.
Similarly, this can happen during ML model development. This is a condition when the ML model performs well on training data. But it is not generalizing on test data. In other words, the model is not predicting accurate results on unseen data. Generally, this condition occurs when the ML model is very complex.
Cause for Overfitting in ML
Overfitting in machine learning occurs when an ML model does not learn underlying patterns in the training data. Here is the list of factors that can cause overfitting in the machine learning model.
- Highly Complex machine learning model
- Insufficient training data.
- Noise in data such as outliners
- Lack of regularization
- Non-representative training data.
How to solve Overfitting in Machine Learning
We can use following techniques to solve overfitting problems in ML algorithms.
- Strike a balance between model complexity and required accuracy.
- Increase the number of data points in the training set.
- Make sure training data is representative.
- Use regularization and evaluation techniques.
- Right feature selection.
Underfitting in Machine Learning
In layman’s language, from a student’s perspective, underfitting is like not preparing for an exam at all. As a result, there is a possibility you will not be able to answer the questions during the exam.
Similarly, this can happen during ML model development. This is a condition when the ML model does not perform well on training as well as test data. In other words, the model is not predicting accurate results on training as well as unseen data. Generally, this condition occurs when the ML model is very simple.
Cause for Underfitting in Machine Learning
Underfitting in machine learning occurs when the model is too simple to capture the underlying patterns in the training data. Here is the list of factors that can cause underfitting in machine learning:
- The ML model is too simple to generalize.
- Input features are not enough to determine the underline pattern in data.
- The number of training samples is not enough to determine the underlying pattern in the data.
- The condition for data independence is not fulfilling.
- Over regularization.
How to solve underfitting in Machine Learning
We can use the following techniques to solve undefitting problems in ML algorithms.
- Choose a more complex ML model.
- Decrease regularization
- Add more relevant features.
- Increase the number of training data points.
- Transform existing features into new features.
- Use the ensemble technique.