Today, we will discuss what can go wrong with your machine-learning algorithms. Or What are the common problems or issues in machine learning algorithm developments? We can solve the common machine learning problem if we know where it is.
Table of Contents
ToggleMajor Problems in Machine Learning Algorithm Developments
The major problem in the Machine Learning model can be from.
- Poor-quality Data: Training and test data
- Poor Performing Algorithm
We can resolve a poor-performing algorithm problem by iterating multiple ML algorithms. But if the problem is with input data, any number of iterations will not give good results.
Therefore, the first step when developing machine learning algorithms is to analyze and improve input data. We also call this process exploratory data analysis.
Data related Issues in Machine Learning
Here is the list of data related problems we face during ML model development.
- Inadequate Training Data
- Non-representative Training Data
- Poor Quality Data: Error, outliners, and Noise
- Irrelevant Features
- Overfitting Training Data
- Underfitting Training Data
- Categorical Features
Inadequate training data: A Major Issues in Machine Learning
Machine learning algorithms are hungry for data. The higher the excellent quality input data we have, the more generalized will be the machine learning algorithm.
- A simple machine-learning task may work with hundreds or thousands of data points.
- We may need millions of data points for complex ML tasks such as speech or image recognition.
Apart from the quantity of data, we need to ensure the data does not have noise or is incorrect.
Example of inadequate training data
Let’s consider an example where we got feature A, and we are predicting the value of the unknown variable “X”.
Is it possible to draw a generalized line with these 3 data points?
Take a pause and think about this.
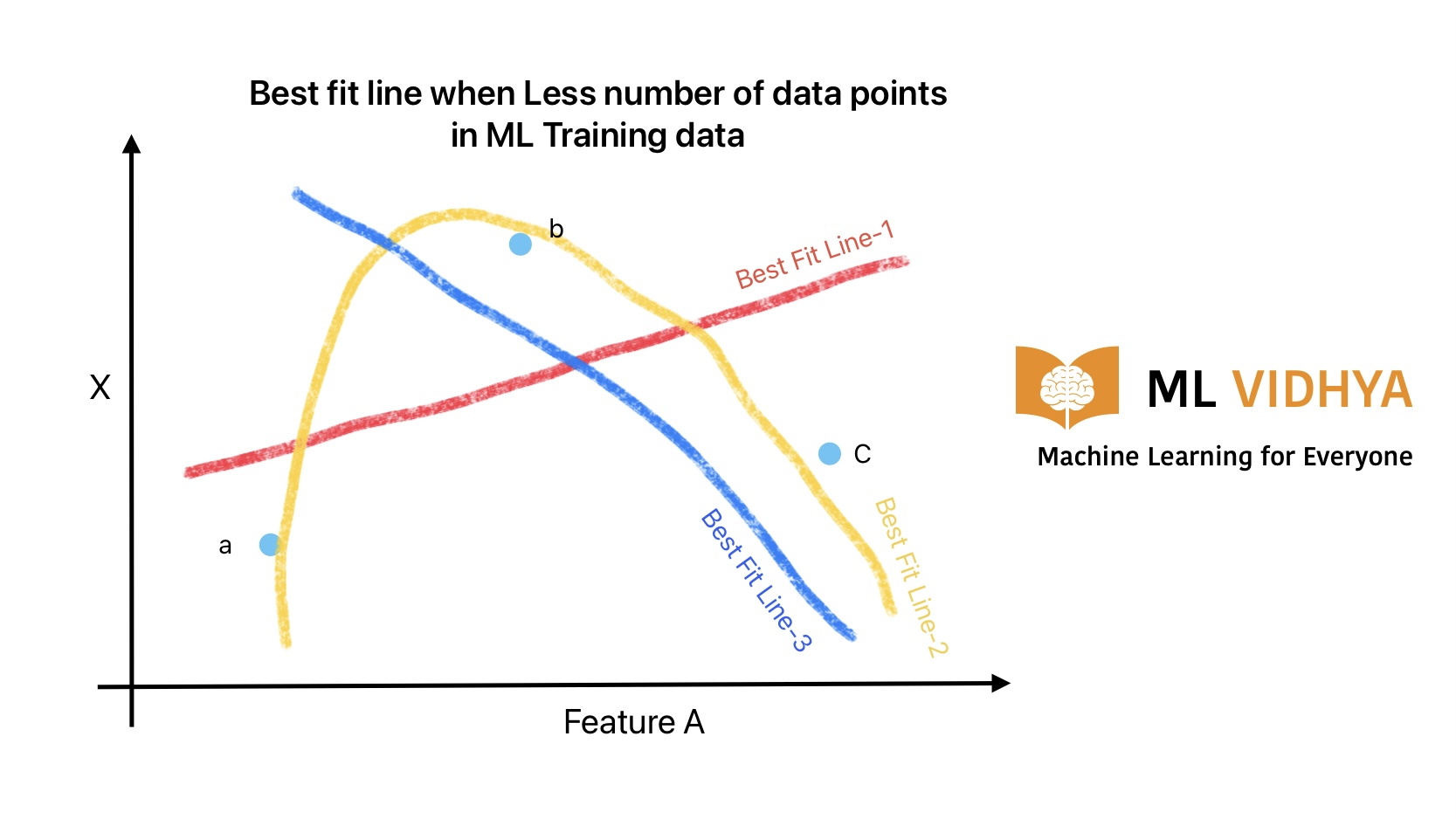
There can be multiple options to draw a best-fit line. But as of now, we can consider the following three options.
- A parabolic curve.
- A line going from a to c (considering b is an outliner).
- A line from A to B and so on.
What if we increase the number of data points?
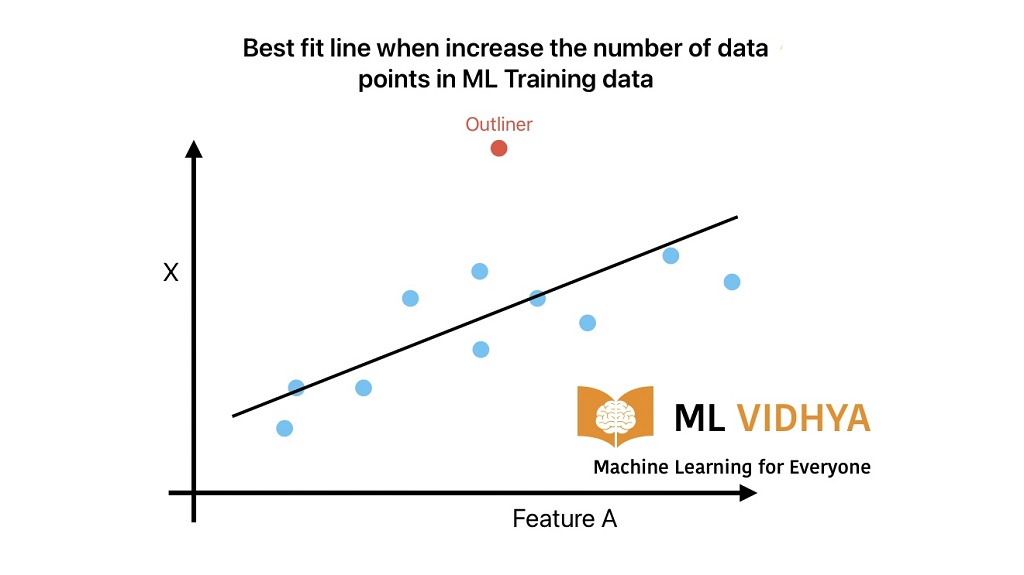
We can easily find the best-fit line generalizing on all training data.
Therefore, we can conclude that the machine learning model improves with the increase in the number of data points. However, an increase in the number of data points will not guarantee an improvement in ML model performance.
Challenges in Machine Learning if we have a large data set
More than required data points have their problems. If you have lots of data points, let’s say a million. You will need high computing resources to train a machine-learning model on a million data points.
More data improves ML model accuracy, but we always need a tradeoff between the required accuracy and the available computing power.
Non-representative Training Data
What is our end goal while developing a machine-learning algorithm?
Our final goal is to ensure that the machine learning model generalizes on unseen data. We can not provide good predictions on unseen data if we do not have true representative training data. This is one of the biggest issues that engineers face in machine learning.
Example for the Impact of Non-representative Training Data
We will understand the impact of non-representative training data using an example of a skilled workforce salary with age. In this example we want to predict a person salary with his/her age.
In reality, multiple parameters can affect the salary. But for the simplicity of understanding, we are considering age features only.
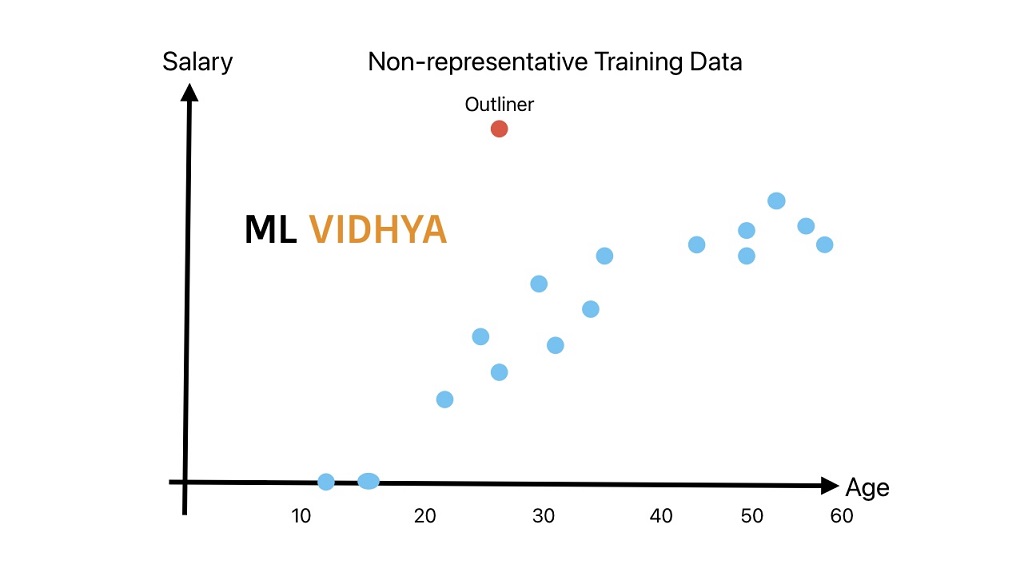
As shown in above graph, we trained our machine learning model till the age of 55 years. If you want to predict the salary of a 30-year-old skilled worker, more likely you will get the best results.
But if you want to predict the salary of a 75-year-old person. The model will extrapolate the trend line and will give you a prediction.
Now the question is: Whether the predicted value is correct?
In most cases, our prediction will be wrong because most get retired and live on pension money after 60 years of age. Generally, the pension money is less than what they earn while working.
Therefore, a lack of representative or non-representative training data results in wrong predictions. It is one of the major issues in machine learning developments.
Example-2 For non-representative training data
Sometimes we use sampling data for the training of ML algorithms. But the sampling data does not represent the actual population. As a result, the ML model does not generalize on unseen data.
Poor-Quality Data: Major Cause of Problem in Machine Learning
It will become hard for the ML algorithm to identify a pattern in data if it has errors, outliers, and noise. Let’s understand with an example:
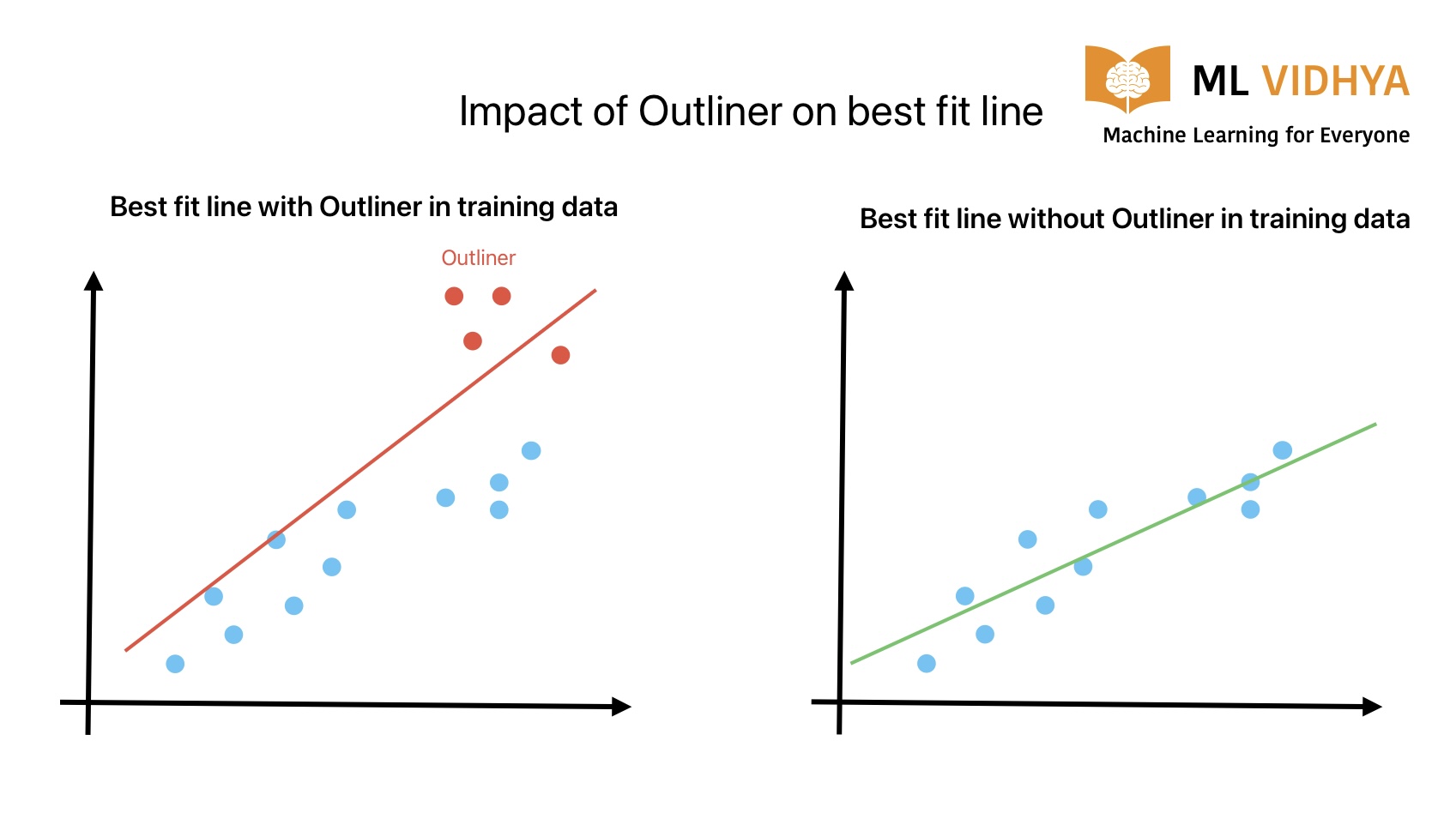
In the left image, the best-fit line is more tilted when there is an outliner in training data. The best-fitted line rotates clockwise as soon we remove the outlines. The new model will give better results on training and validation data.
Therefore, ML experts always recommend cleaning the data before applying machine learning algorithms. A Clean data will resolve various issues in machine learning developments.
Irrelevant Features: Garbage In - Garbage Out
Machine learning algorithms output according to input training data (Garbage-In Garbage-Out). You must understand the business problem in detail before developing a machine-learning algorithm. It helps in selecting the right features and machine learning algorithms for your application.
Let’s understand this with our last example of age vs salary.
Is the salary directly proportional to your age?
The answer is no.
Number of years of experience, education, knowledge, background, and working status (working or not working) are the factors that affect a person’s earnings, not age.
Therefore, you will not get good results if we consider age as the only factor that affects a person’s earnings.
Overfitting is one of the most common issues we face during ML algorithm development. It is similar to something where we make our decisions based on fewer data points.
In ML, it happens when the ML algorithm is performing very well on training data but not on validation data.
Example of overfitting classification:
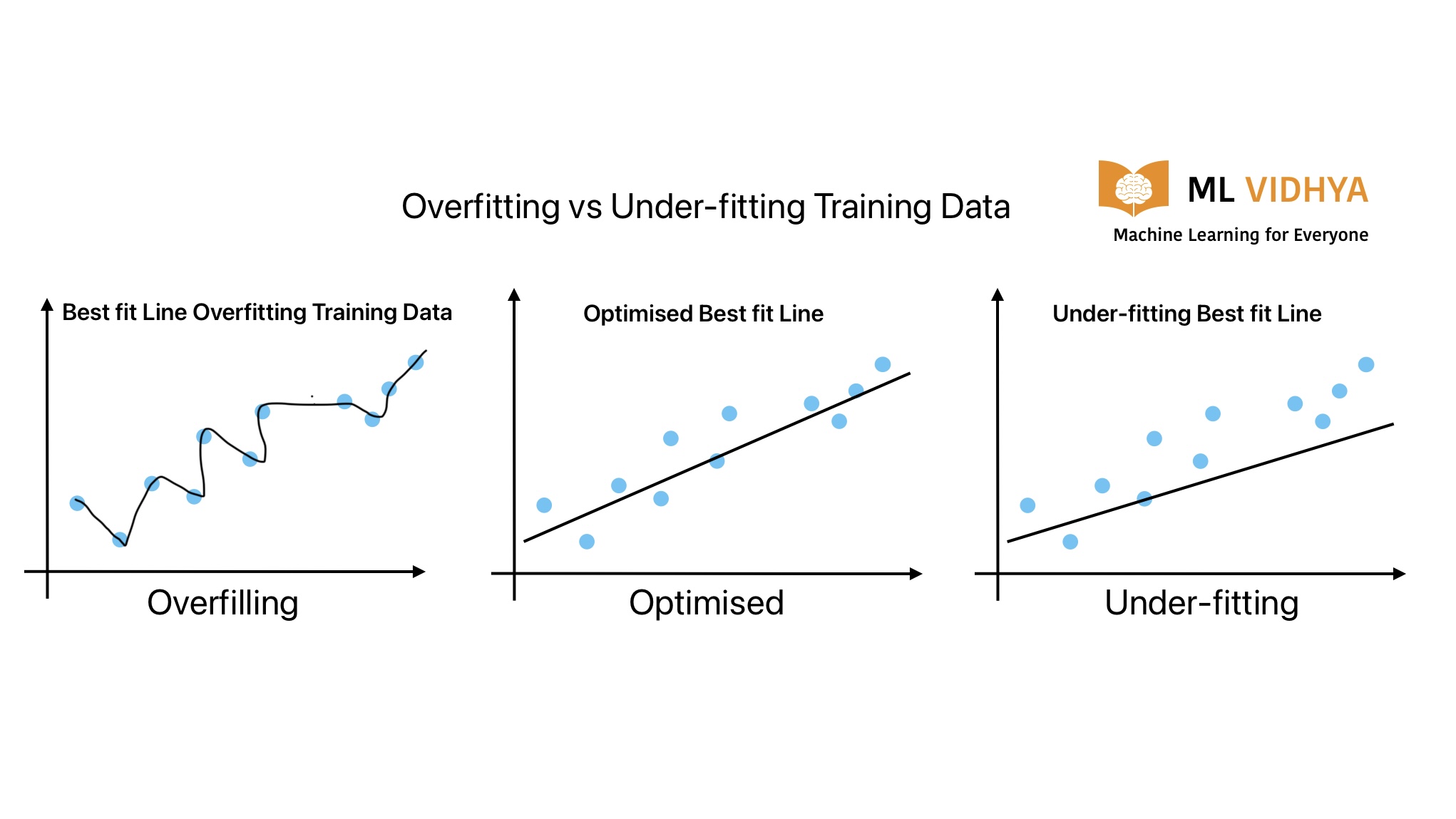
How to prevent Over-fitting problem in Machine Learning
We can resolve overfitting problem in machine learning by implementing following techniques.
- Early Stopping
- Inadequate training data
- Feature Selection
- Cross-Validation
- Data Augmentation
- Regularization
- Ensemble Techniques
Under-fitting is just the opposite of over-fitting. It is also a common issues in machine learning algorithms. This ML algorithm is not generalized even on the training data because the model is too simple to fit the training data.
How to prevent under-fitting in Machine Learning?
We can resolve underfitting problem in machine learning by implementing following techniques.
- Select a powerful ML model. Increasing the degree of freedom, increases model complexity.
- Feature Engineering: selecting the right features or combination of multiple features.
- Reduce the noise in the data.
Categorical Features
Data for machine learning is available as numeric, categorical (2 bedroom, 3-bed room, etc.), images, voice, etc. The machine learning algorithms understand only numerical data. Therefore categorical data needs to be converted into numerical data.
If there are very few categories, then it’s ok. Categorical data becomes a big issues in machine learning in case we have hundreds or thousands of categories.
- Either we need lots of computing power.
- Lose some data during conversion.
Key Takeaways
Machine Learning is an evolving technology and data is a fuel for machine learning algorithms. We can resolve many problems and issues in machine learning just by improving input data quality.